
FastAnimate: Towards Learnable Template Construction and Pose Deformation for Fast 3D Human Avatar Animation
Annual AAAI Conference on Artificial Intelligence, 2026
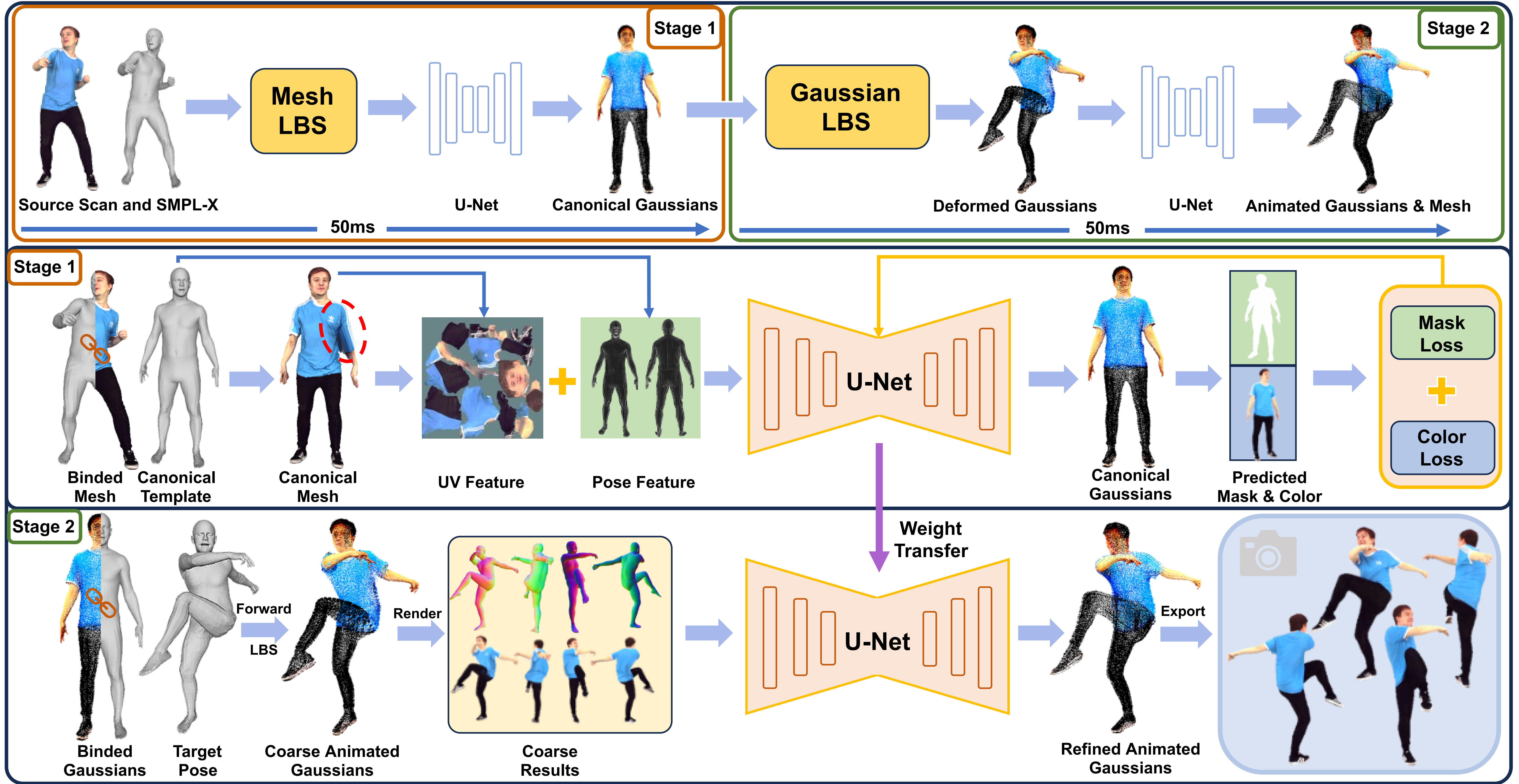 This framework consists of two stages: In the first stage, we decouple the UV feature and pose feature from canonical mesh to build canonical Gaussians with the given human scans and SMPL-X canonical template. In the second stage, we utilize the LBS to drive canonical Gaussians to form coarse animated Gaussians. To further improve the animation quality, we utilize a coarse geometry refinement module to obtain high-fidelity refined animated human Gaussians. By leveraging FastAnimate, we can achieve robust 3D human animation results with enhanced texture quality and pose correctness.
This framework consists of two stages: In the first stage, we decouple the UV feature and pose feature from canonical mesh to build canonical Gaussians with the given human scans and SMPL-X canonical template. In the second stage, we utilize the LBS to drive canonical Gaussians to form coarse animated Gaussians. To further improve the animation quality, we utilize a coarse geometry refinement module to obtain high-fidelity refined animated human Gaussians. By leveraging FastAnimate, we can achieve robust 3D human animation results with enhanced texture quality and pose correctness.
Abstract
3D human avatar animation aims at transforming a human avatar from an arbitrary initial pose to a specified target pose using deformation algorithms. Existing approaches typically divide this task into two stages: canonical template construction and target pose deformation. However, current template construction methods demand extensive skeletal rigging and often produce artifacts for specific poses. Moreover, target pose deformation suffers from structural distortions caused by Linear Blend Skinning (LBS), which significantly undermines animation realism. To address these problems, we propose a unified learning-based framework to address both challenges in two phases. For the former phase, to overcome the inefficiencies and artifacts during template construction, we leverage a U-Net architecture that decouples texture and pose information in a feed-forward process, enabling fast generation of a human template. For the latter phase, we propose a data-driven refinement technique that enhances structural integrity. Extensive experiments show that our model delivers consistent performance across diverse poses with an optimal balance between efficiency and quality, surpassing state-of-the-art (SOTA) methods.